

Understanding the financial and monetary penalties of pure disasters is a serious concern for researchers and policymakers. The way in which wherein overlapping pure catastrophe methods work together, as exemplified by the current fires in Los Angeles being exacerbated by robust winds, is a serious space of examine in environmental science however has obtained comparatively little consideration within the economics literature. Analyzing these potential interactions would probably be necessary for monetary establishments, since such assessments would, in lots of cases, improve the estimated monetary affect of a given pure catastrophe. In our current Workers Report, we develop a way of figuring out catastrophe methods in pure catastrophe knowledge, such because the Spatial Hazard Occasions and Loss Database (SHELDUS), and use it to argue that the economics and finance literatures could have missed some sources of systemic threat.
What Is Clustering?
We outline clustering in pure catastrophe occurrences because the tendency for pure disasters to be concentrated in sure geographic areas and/or quick intervals of time. On this put up, we give attention to spatial clustering (that’s, clustering in geographic areas), however the Workers Report additionally presents outcomes on temporal clustering (that’s, clustering throughout time). Clustering may have necessary implications for the way we perceive pure disasters if they’ve spatial spillover results. For instance, if neighboring counties are depending on frequent emergency sources for support in restoration, these sources could also be strained if all of those counties are concurrently affected by disasters. For these causes, it is very important determine clusters of pure disasters throughout area in financial knowledge on pure disasters.
A Novel Strategy for Figuring out Pure Catastrophe “Clusters”
For a given pair of neighboring counties, we ask whether or not they each expertise damages from the identical hazard kind in the identical month, as reported by SHELDUS. In that case, they’re handled as being a part of the identical cluster. This method is repeated till no further county pairs could be linked. Within the left panel of the determine beneath, we see the cluster of counties that may be linked to Harris County, Texas (Houston) when Hurricane Harvey struck in August 2017. As compared, the right-hand panel exhibits the footprint of counties recognized within the official Hurricane Harvey Catastrophe Declaration by FEMA. The similarity of the recognized cluster with FEMA’s declared catastrophe space exhibits that our algorithm can determine main disasters within the knowledge with cheap accuracy.
Evaluating the Harris County August 2017 Spatial Cluster (left) with the FEMA Hurricane Harvey catastrophe (proper)
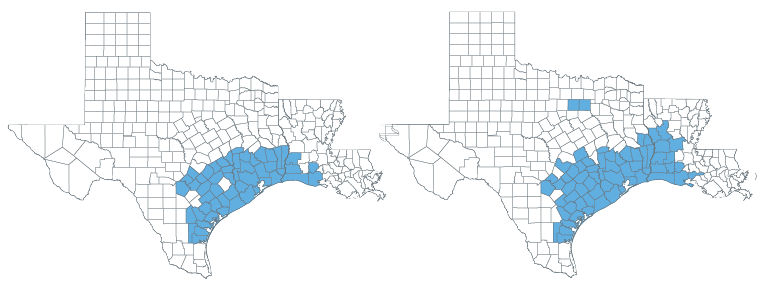
Notes: These maps illustrate the set of counties which might be included within the Harris County August 2017 spatial cluster (left), as obtained by the described clustering process, and the set of counties included within the “Hurricane Harvey” Presidential Catastrophe Declaration (proper).
Why Does “Clustering” Matter?
Pure catastrophe damages knowledge which might be aggregated on the cluster stage could have totally different distributional properties in comparison with normal panel knowledge, that are measured on the county stage. The chart beneath exhibits a comparability of the damages in the usual SHELDUS disasters knowledge (that’s, panel knowledge on the county stage), relative to a dataset of damages aggregated on the cluster stage utilizing our methodology. Curiously, we have a tendency to watch extra excessive damages when analyzing damages on the cluster stage. The distinction between the distributions of damages utilizing county- and cluster-level knowledge highlights the way it could also be simpler to seize the results of maximum disasters when incorporating clustering into analyses of pure catastrophe outcomes.
The Distribution of Catastrophe Damages In accordance with Clusters and Counties
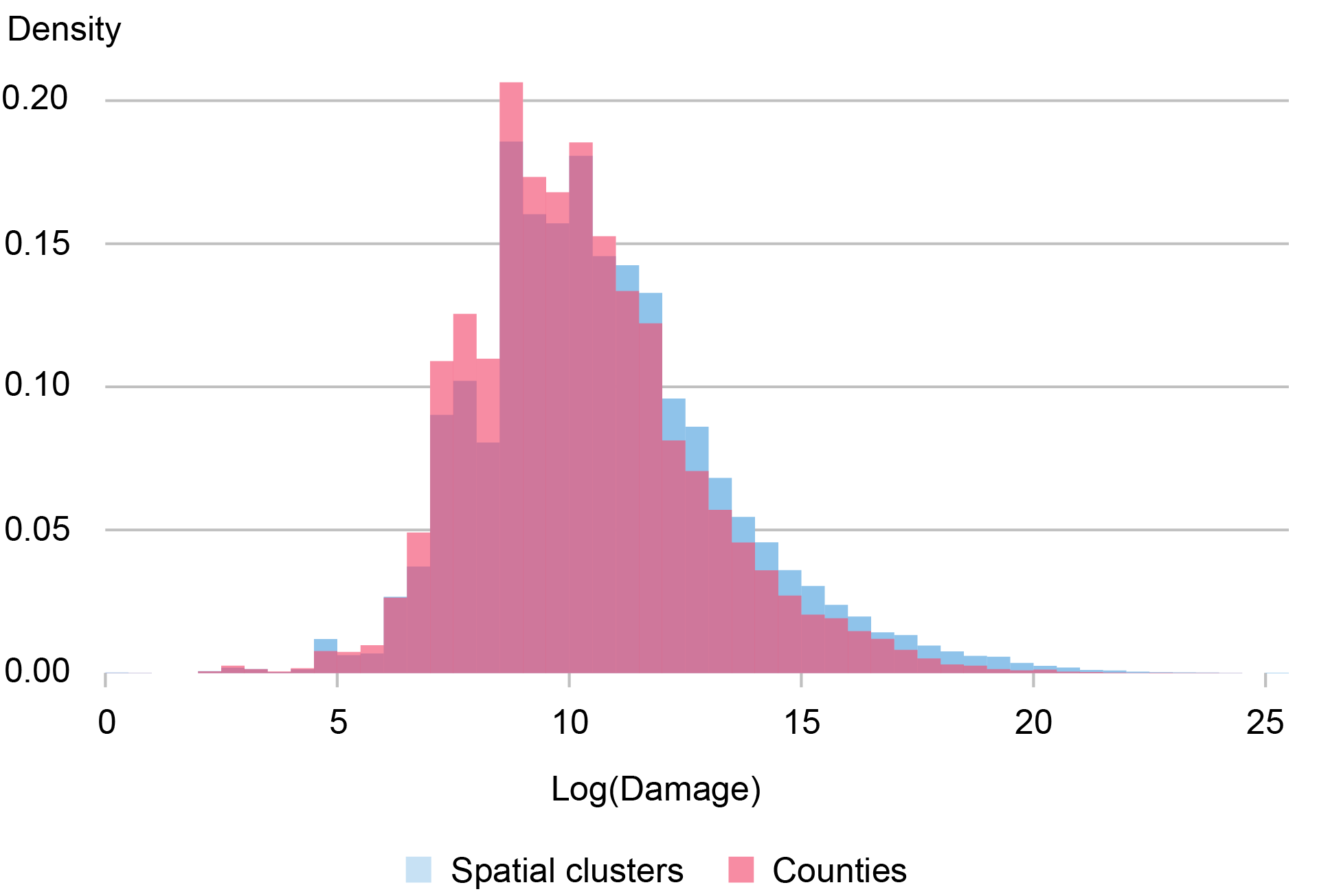
Notes: This chart exhibits the distribution of the log of whole damages outlined on the spatial cluster stage, alongside the distribution of the log of whole damages outlined on the county stage. Information on pure disasters are sourced from SHELDUS and run from 2000 although 2020.
To additional discover whether or not bigger clusters are typically extra damaging, we take a look at how catastrophe damages range in keeping with the scale of a cluster, measured by the variety of affected counties within the cluster. The chart beneath means that as relative dimension will increase, common damages develop rapidly. This chart, together with further evaluation in our Workers Report, means that counties are likely to expertise disproportionately extra catastrophe harm when they’re a part of clusters that have massive quantities of harm. That is suggestive of the existence of the kinds of catastrophe damage-related spillover results that had been mentioned above.
Variations in Catastrophe Injury in Phrases of Cluster Measurement
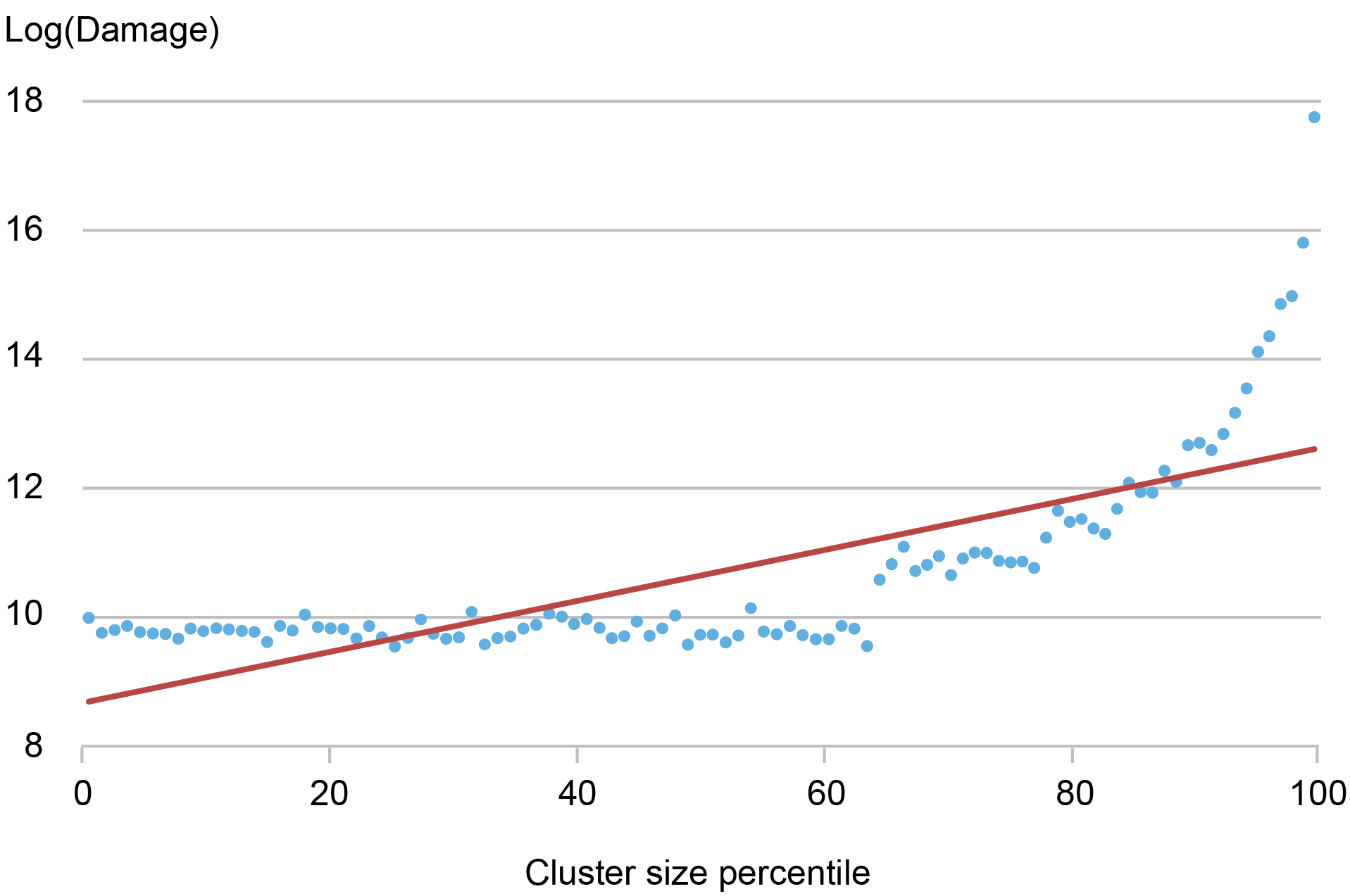
Notes: This chart exhibits the anticipated log harm of a cluster conditional on the scale of the cluster it lies in. Information on pure disasters are sourced from SHELDUS and run from 2000 although 2020.
Lastly, we ask whether or not sure hazard sorts seem to trigger totally different ranges of harm relying on whether or not county- or cluster-level knowledge are used. The chart beneath shows the connection between common damages for varied hazard sorts primarily based on county-level knowledge and people primarily based on cluster-level aggregates. The scatter factors lie above the 45-degree line, implying that each one hazard sorts seem extra harmful when utilizing cluster-level aggregates fairly than county-level knowledge. This impact is particularly pronounced for sure hazard sorts: Droughts are the ninth-most extreme hazard kind when utilizing county-level knowledge however are the second-most extreme hazard kind when aggregating damages to the cluster stage, presumably as a result of the common drought happens in a cluster of about thirty counties, relative to a median cluster dimension of 4 counties throughout all hazard sorts. Damages from droughts due to this fact are typically unfold out throughout extra counties. In consequence, analyses of catastrophe damages on the county stage could lead researchers to underestimate the severity of sure hazard sorts when these hazard sorts are likely to happen in massive clusters.
Relationship Between Spatial Cluster Injury and County Injury by Hazard Sort

Notes: This chart exhibits the connection between the common county-level harm in comparison with the common spatial cluster-level harm conditional on a given hazard kind being current. Information on pure disasters are sourced from SHELDUS, and run from 2000 although 2020.
Remaining Phrases
Impressed by an necessary thought from the environmental science literature, we develop a way for figuring out clusters of disasters. We present that this method is economically significant because it illustrates the heterogeneities in damages by pure catastrophe kind. Failing to account for clustering could have implications for each policymakers and practitioners. As an example, if clustering is ignored, policymakers could insufficiently put together for sure hazard sorts that are likely to happen in massive spatial clusters, reminiscent of droughts. Furthermore, monetary establishments could not accurately quantify pure catastrophe threat of their portfolios with respect to areas which might be probably uncovered to low-probability, high-impact disasters. Lastly, if catastrophe damages are correlated throughout totally different areas as a result of phenomenon of spatial clustering, it might be tough to acquire insurance coverage for property situated in such areas. This might improve the chance of credit score rationing in areas uncovered to pure disasters, particularly in markets the place insurance coverage is necessary, reminiscent of the true property market. Due to this fact, our venture sheds mild on a possible supply of systemic threat that banks, insurers, and policymakers could wish to bear in mind.

Jacob Kim-Sherman is a analysis analyst within the Federal Reserve Financial institution of New York’s Analysis and Statistics Group.

Lee Seltzer is a monetary analysis economist within the Federal Reserve Financial institution of New York’s Analysis and Statistics Group.
The best way to cite this put up:
Jacob Kim-Sherman and Lee Seltzer, “What Is Pure Catastrophe Clustering—and Why Does It Matter for the Financial system?,” Federal Reserve Financial institution of New York Liberty Avenue Economics, September 2, 2025, https://libertystreeteconomics.newyorkfed.org/2025/09/what-is-natural-disaster-clustering-and-why-does-it-matter-for-the-economy/
BibTeX: View |
Disclaimer
The views expressed on this put up are these of the creator(s) and don’t essentially mirror the place of the Federal Reserve Financial institution of New York or the Federal Reserve System. Any errors or omissions are the accountability of the creator(s).